Sistema de reconocimiento facial con robot cuadrúpedo para aplicaciones de seguridad y vigilancia
Introducción
La idea del proyecto consiste en implementar un sistema de reconocimiento facial en el robot cuadrúpedo Go1, utilizando (idealmente) sus cámaras incorporadas.
Go1 cuenta con un conjunto de computadores Jetson Nano (cada uno de éstos conectados a una cámara estéreo) y una tarjeta Raspberry Pi (encargada, dentro de otras cosas, de la conectividad WiFi), por lo que es plausible ejecutar cargas computacionales relativamente elevadas en él.

Antes de explicar cómo se implementa el sistema, es necesario entender el funcionamiento de los algoritmos de reconocimiento facial:
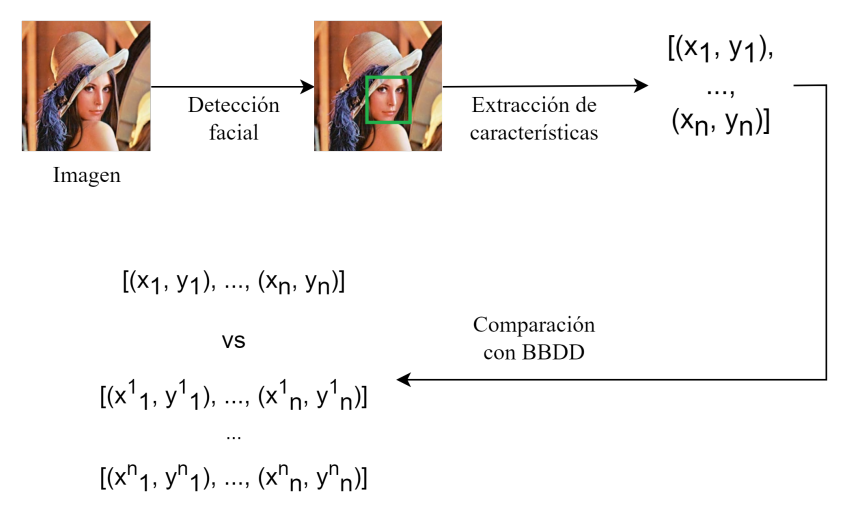
Detección facial
Tal como lo indica su nombre, esta etapa se encarga de identificar la zona de la imagen donde hay presencia de un rostro utilizando un algoritmo de detección de objetos entrenado para captar caras.
Extracción de características
Una vez identificado el rostro a reconocer, se procede a extraer la informacion contenida en éste, la cual es representada como una estructura de datos, generalmente un vector.
Reconocimiento facial
Finalmente, los datos anteriores son comparados con aquellos registrados previamente en la base de datos y en la comparación donde se cumpla cierto criterio (dado que se pueden utilizar varios para este propósito) ocurre el reconocimiento facial.
Dificultades
Si bien las etapas anteriores parecen sencillas de implementar, una de las mayores dificultades que se tuvo para hacerlo fue el hardware del robot. En primer lugar, la calidad de las imágenes era bastante mala, si bien se intentó reducir su resolución esto implicaba trabajar con imágenes más pequeñas, lo que dificulta realizar la primera etapa de la detección facial, dado que en un frame generalmente los rostros ocupan una pequeña área en la imagen . En segundo lugar, las cámaras era de tipo "ojo de pez", es decir, poseen un campo de visión mayor a costa de introducir distorisón en las imágenes, lo anterior se puede entender mejor con el siguiente esquema:
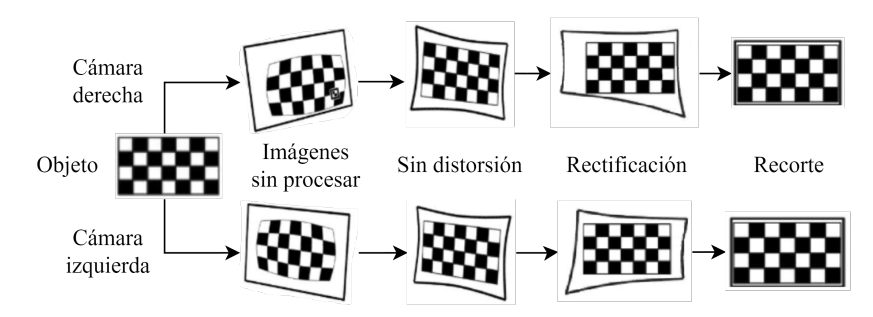
Era necesario eliminar esa distorsión dado que en ciertas situaciones impide que se pueda aplicar el algoritmo de detección facial, el proceso para quitar este ruido se denomina rectificación, lo que permite obtener una imagen sin el efecto "ojo de pez", pero se pierde información en el proceso, dado que el último paso es recortar la imagen.
Diseño de la arquitectura del sistema
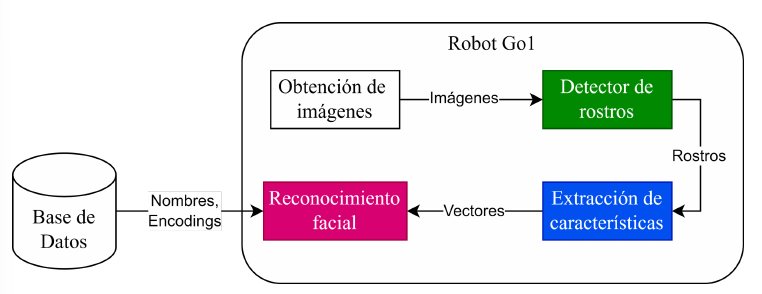
Se proponen tres arquitecturas posibles:En el robot
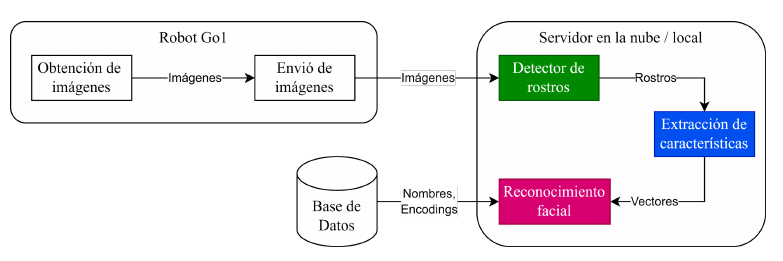
En un servidor en la nube / local
Híbrida
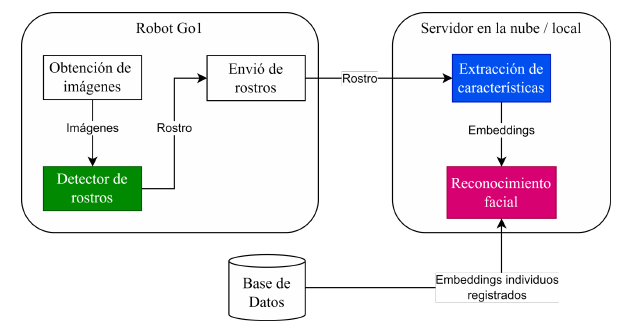
- Independientemente de la arquitectura a implementar será necesario transmitir internamente las imágenes captadas por la cámara frontal hacia otra Jetson Nano para realizar el procesamiento.
- La implementación para la transmisión interna la ofrece el fabricante dentro de su SDK.
- El adaptador WiFi es sólo necesario para la implementación en el servidor e híbrida.
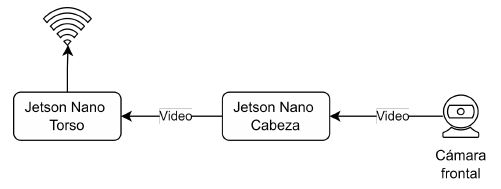
Requerimientos funcionales
Se consideraron más requerimientos tanto funcionales como no funcionales, sin embargo en las tablas se indican las más relevantes.
Requerimientos no funcionales

Evaluación de las arquitecturas
G: garantizado, NG: no garantizado y MG: medianamente garantizado.Según requerimientos funcionales

- Implementación en servidor no garantiza funcionamiento en tiempo real debido al alto uso de ancho de banda y latencia para la transmisión de imágenes desde el robot hacia el servidor.
- Se intentó reducir tiempos de transmisión enviando frames más pequeños hacia el servidor y aumentando su tamaño en éstos para poder realizar detección facial.
Según requerimientos no funcionales

- Implementación sólo en el robot es vulnerable a manipulaciones maliciosas, se aumenta el uso de la batería y es poco escalable.
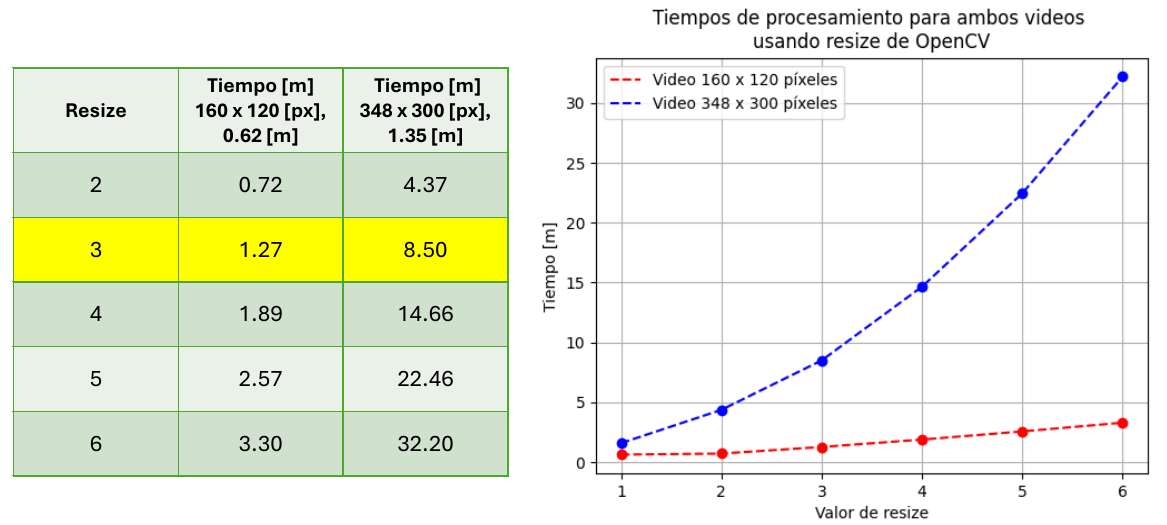
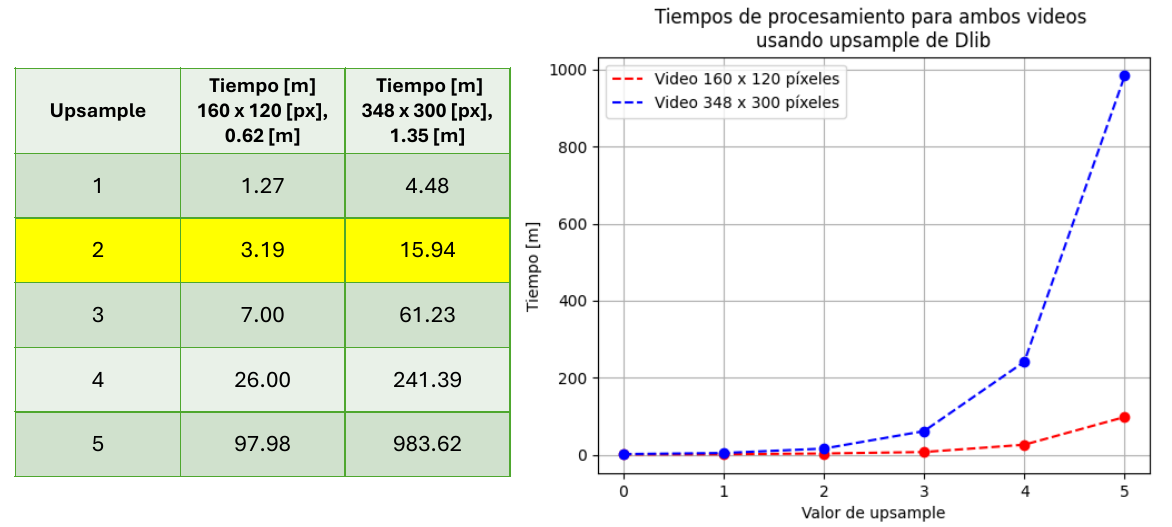
Tiempos de procesamiento al aumentar tamaño de imagen en el servidor
Para corroborar que la implementación en el servidor no permite la transmisión en tiempo real de los frames, se grabaron dos videos de resoluciones y duración diferentes, pequeños (160 x 120 [px] y 348 x 300 [px]) y por ende relativamente rápidos de enviar al servidor. Una vez recibidos en éste, se procesaron frame por frame aumentando su resolución para facilitar el reconocimiento facial con tres métodos diferentes y se midió el tiempo total, obteniendo los siguientes resultados:
Con la función resize() de OpenCV
Con la función upsample() de Dlib
Utilizando Super Resolution (SR)
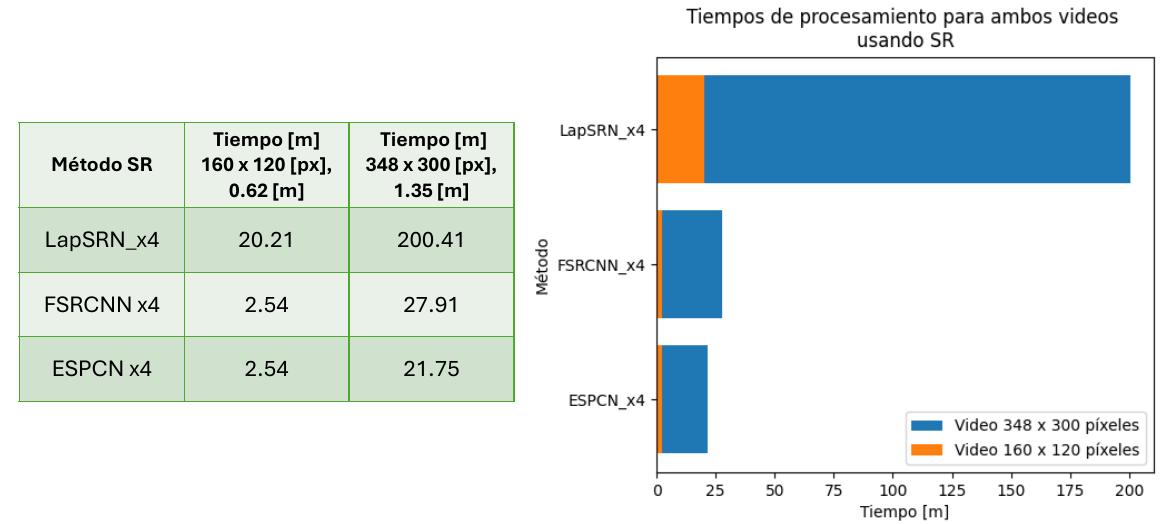
Teniendo en consideración lo mencionado anteriormente, es seguro indicar que las implementaciones en el robot y servidor son poco viables y por lo tanto se decide continuar con la solución híbrida.
Resultados solución híbrida
Si bien con la implementación híbrida se mejoró considerablemente el tiempo de envió, dado que el servidor sólo recibía la imagen del rostro, la calidad de éstas era bastante mala como para que el módulo de extracción de características realizará una operación adecuanda. En la mayoría de los casos las imágenes de los rostros tenían el siguiente aspecto: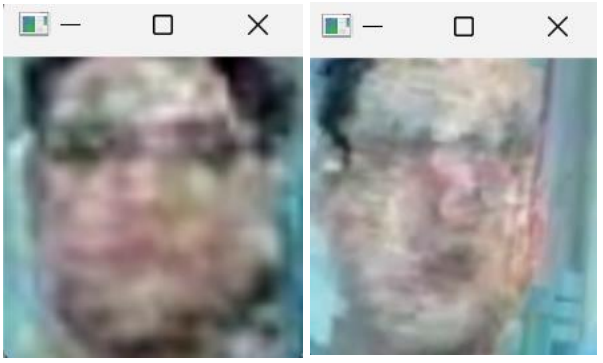
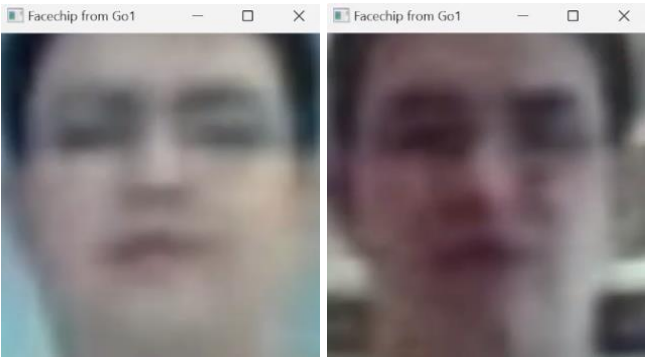
Con lo anterior se determinó que la calidad producida a partir de los aspectos ópticos de los lentes de las cámaras del robot no permiten realizar reconocimiento facial de forma óptima. Sin embargo, aún quedaba la posibilidad de utilizar una cámara externa.
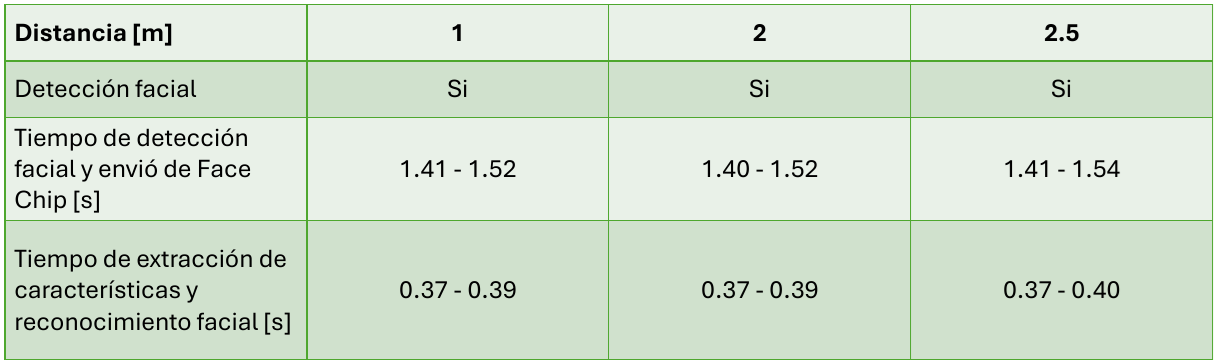
Resultados solución híbrida usando una webcam externa
La configuración física consistió en montar la webcam sobre la cabeza del robot (usando claramente cinta aislante como buen ing electrónico):
Conclusiones
- Precedente para la futura implementación de sistemas de reconocimiento facial en plataformas móviles.
- Uso de arquitectura flexible y modular permite la aplicación del sistema en diferentes contextos.
- Posibilidad de implementar soluciones basadas en reconocimiento facial en entornos que no garantizan condiciones ideales para los algoritmos.